My student Torben has just published his Android augmented reality app SINLA in the Android market. Our aim is to not only publish a cool app but to also use the market for a user study. The application is similar to Layar and Wikitude but we believe that the small mini-map you find in existing application (the small map you see in the lower right corner in the image below) might not be the best solution to show the users objects that are currently not in the focus of the camera.

We developed a different visualization for what we call “off-screen objects” that is inspired by off-screen visualizations for digital maps and navigation in virtual reality. It based on arrows pointing towards the objects. The arrows are arranged on a circle in a 3D perspective. Check out the image below to get an impression how it looks.
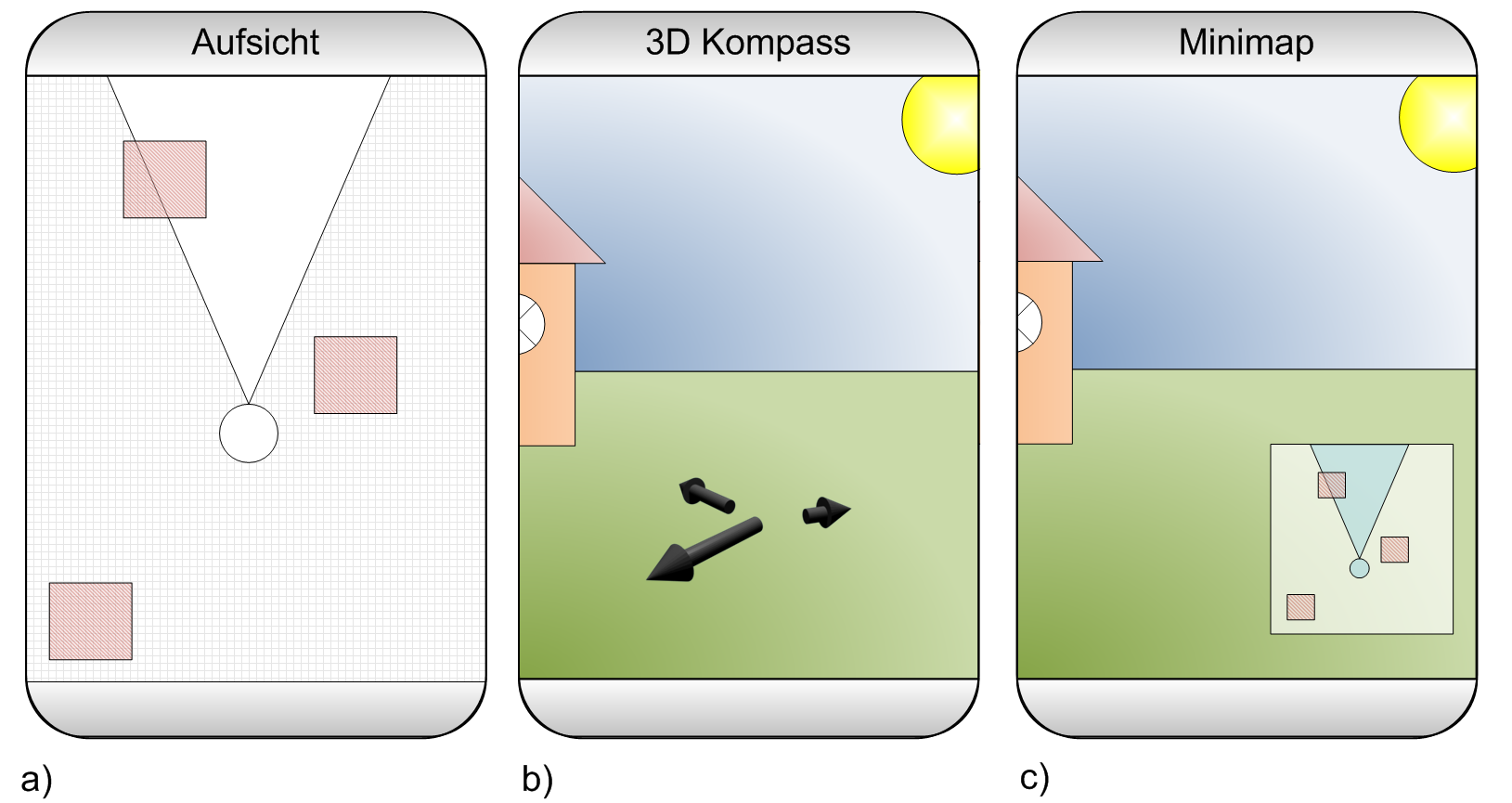
Its our first try to use a mobile market to get feedback from real end users. We compare our visualization technique with the more traditional mini-map. We collect only very little information from users at the moment because we’re afraid that we might deter users from providing any feedback at all. However, I’m thrilled to see if we can draw any conclusion from the feedback we get from the applications. I assume that this is a new way to do evaluations which will become more important in the future.
